Data wrangling
Taller R Octubre 28
Anabelle Laurent
¡Bienvenidos! 😄
¡Bienvenidos! 😄
En esta presentacion vamos a aprender como manejar o “domar” datos (data wrangling, en inglés).
¡Bienvenidos! 😄
En esta presentacion vamos a aprender como manejar o “domar” datos (data wrangling, en inglés).
El objectivo es de tener datos en una forma conveniente para su visualizacíon y analysis.
- que cada columna sea una variable
- que cada fila sea una observación
- que cada celda sea un valor
¡Bienvenidos! 😄
En esta presentacion vamos a aprender como manejar o “domar” datos (data wrangling, en inglés).
El objectivo es de tener datos en una forma conveniente para su visualizacíon y analysis.
- que cada columna sea una variable
- que cada fila sea una observación
- que cada celda sea un valor
Por eso vamos a usar tidyverse
Primero: ¿ que es tidyverse ? 🤔

Tidyverse es una colleccíon de R paquetes que ayuda para todo el processo de ciencia de datos
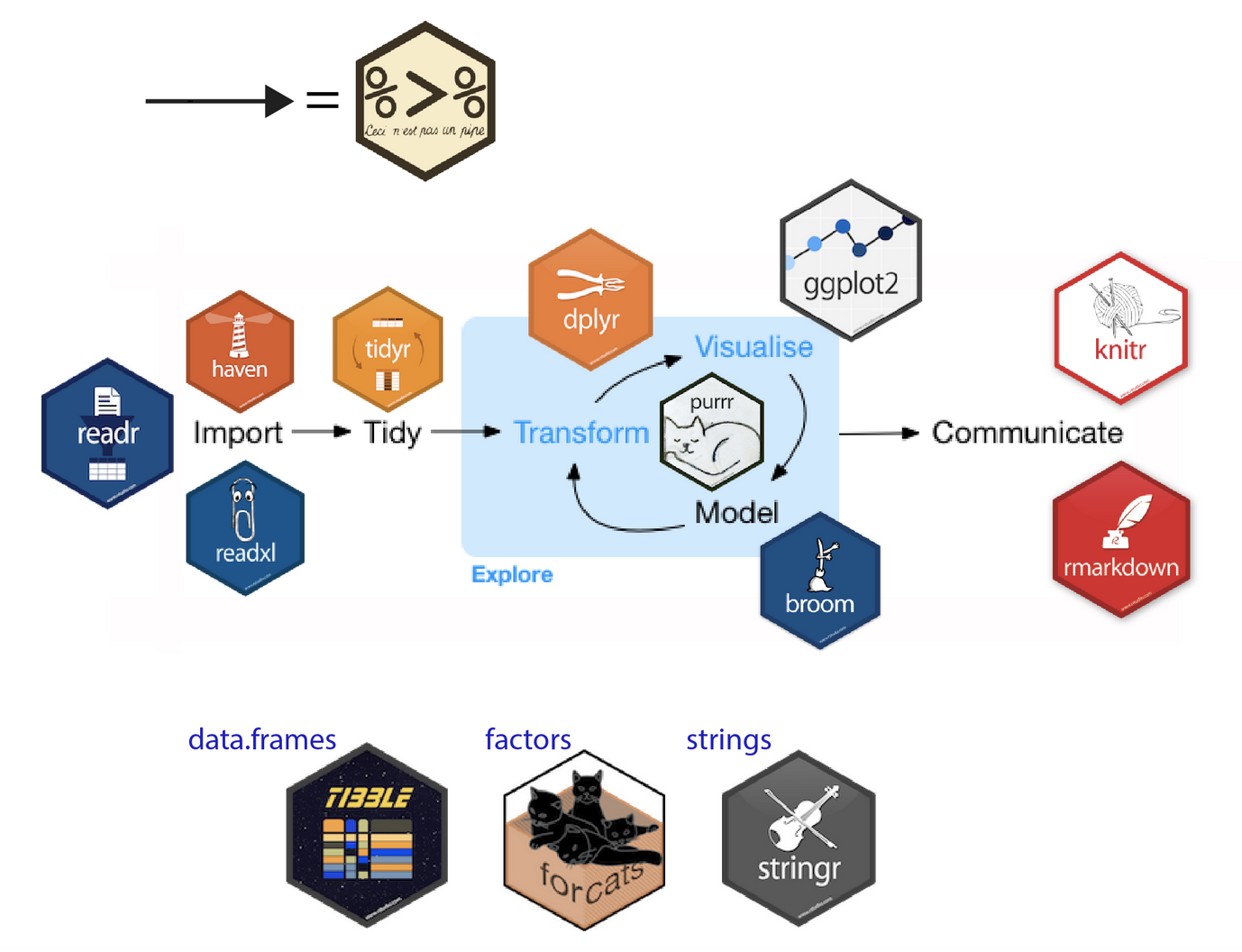
Hoy vamos a explotar dplyr que ayuda para la manupilación de datos.

Las funciones más usadas en dplyr:
- seleccionar variables (SELECT)
- filtrar variables (FILTER)
- mutar y crear nuevas variables (MUTATE)
- sumarizar (SUMMARIZE)
- agrupar las variables (GROUP_BY)
El operador %>% (se llama la tubería, o pipe en ingles), permite expresar de forma clara una secuencia de múltiples operaciones.
Se pueder leer como un “ENTONCES”.
Es un operador específico a tidyverse
install.packages("tidyverse")library(tidyverse)Segundo: los datos que vamos a usar
install.packages("datos")library(datos)paiseshead(paises, n =10) # muestra las "n" primeras lineas de datos# A tibble: 10 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Afganistán Asia 1972 36.1 13079460 740. 6 Afganistán Asia 1977 38.4 14880372 786. 7 Afganistán Asia 1982 39.9 12881816 978. 8 Afganistán Asia 1987 40.8 13867957 852. 9 Afganistán Asia 1992 41.7 16317921 649.10 Afganistán Asia 1997 41.8 22227415 635.SELECT
La funcion SELECT permite de seleccionar columnas por nombre
paises %>% select (pais,anio, poblacion)# A tibble: 1,704 × 3 pais anio poblacion <fct> <int> <int> 1 Afganistán 1952 8425333 2 Afganistán 1957 9240934 3 Afganistán 1962 10267083 4 Afganistán 1967 11537966 5 Afganistán 1972 13079460 6 Afganistán 1977 14880372 7 Afganistán 1982 12881816 8 Afganistán 1987 13867957 9 Afganistán 1992 1631792110 Afganistán 1997 22227415# … with 1,694 more rowspaises %>% select (pais:esperanza_de_vida)# A tibble: 1,704 × 4 pais continente anio esperanza_de_vida <fct> <fct> <int> <dbl> 1 Afganistán Asia 1952 28.8 2 Afganistán Asia 1957 30.3 3 Afganistán Asia 1962 32.0 4 Afganistán Asia 1967 34.0 5 Afganistán Asia 1972 36.1 6 Afganistán Asia 1977 38.4 7 Afganistán Asia 1982 39.9 8 Afganistán Asia 1987 40.8 9 Afganistán Asia 1992 41.710 Afganistán Asia 1997 41.8# … with 1,694 more rowspaises %>% select (-poblacion)# A tibble: 1,704 × 5 pais continente anio esperanza_de_vida pib_per_capita <fct> <fct> <int> <dbl> <dbl> 1 Afganistán Asia 1952 28.8 779. 2 Afganistán Asia 1957 30.3 821. 3 Afganistán Asia 1962 32.0 853. 4 Afganistán Asia 1967 34.0 836. 5 Afganistán Asia 1972 36.1 740. 6 Afganistán Asia 1977 38.4 786. 7 Afganistán Asia 1982 39.9 978. 8 Afganistán Asia 1987 40.8 852. 9 Afganistán Asia 1992 41.7 649.10 Afganistán Asia 1997 41.8 635.# … with 1,694 more rowspaises %>% select(-c(anio, poblacion))# A tibble: 1,704 × 4 pais continente esperanza_de_vida pib_per_capita <fct> <fct> <dbl> <dbl> 1 Afganistán Asia 28.8 779. 2 Afganistán Asia 30.3 821. 3 Afganistán Asia 32.0 853. 4 Afganistán Asia 34.0 836. 5 Afganistán Asia 36.1 740. 6 Afganistán Asia 38.4 786. 7 Afganistán Asia 39.9 978. 8 Afganistán Asia 40.8 852. 9 Afganistán Asia 41.7 649.10 Afganistán Asia 41.8 635.# … with 1,694 more rowsFILTER
la funcion FILTER permite de filtrar les lineas que respectan una condición
paises %>% filter (pais=="Ecuador")# A tibble: 12 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Ecuador Américas 1952 48.4 3548753 3522. 2 Ecuador Américas 1957 51.4 4058385 3781. 3 Ecuador Américas 1962 54.6 4681707 4086. 4 Ecuador Américas 1967 56.7 5432424 4579. 5 Ecuador Américas 1972 58.8 6298651 5281. 6 Ecuador Américas 1977 61.3 7278866 6680. 7 Ecuador Américas 1982 64.3 8365850 7214. 8 Ecuador Américas 1987 67.2 9545158 6482. 9 Ecuador Américas 1992 69.6 10748394 7104.10 Ecuador Américas 1997 72.3 11911819 7429.11 Ecuador Américas 2002 74.2 12921234 5773.12 Ecuador Américas 2007 75.0 13755680 6873.paises %>% filter (anio==1982)# A tibble: 142 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1982 39.9 12881816 978. 2 Albania Europa 1982 70.4 2780097 3631. 3 Argelia África 1982 61.4 20033753 5745. 4 Angola África 1982 39.9 7016384 2757. 5 Argentina Américas 1982 69.9 29341374 8998. 6 Australia Oceanía 1982 74.7 15184200 19477. 7 Austria Europa 1982 73.2 7574613 21597. 8 Baréin Asia 1982 69.1 377967 19211. 9 Bangladesh Asia 1982 50.0 93074406 677.10 Bélgica Europa 1982 73.9 9856303 20980.# … with 132 more rowspaises %>% filter (anio==1982 & pais=="Ecuador")# A tibble: 1 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl>1 Ecuador Américas 1982 64.3 8365850 7214.paises %>% filter (pais %in% c("China","Vietnam") & anio==1982)# A tibble: 2 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl>1 China Asia 1982 65.5 1000281000 962.2 Vietnam Asia 1982 58.8 56142181 707.paises %>% filter (anio > 1962)# A tibble: 1,278 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1967 34.0 11537966 836. 2 Afganistán Asia 1972 36.1 13079460 740. 3 Afganistán Asia 1977 38.4 14880372 786. 4 Afganistán Asia 1982 39.9 12881816 978. 5 Afganistán Asia 1987 40.8 13867957 852. 6 Afganistán Asia 1992 41.7 16317921 649. 7 Afganistán Asia 1997 41.8 22227415 635. 8 Afganistán Asia 2002 42.1 25268405 727. 9 Afganistán Asia 2007 43.8 31889923 975.10 Albania Europa 1967 66.2 1984060 2760.# … with 1,268 more rowspaises %>% filter(anio <=1962)# A tibble: 426 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Albania Europa 1952 55.2 1282697 1601. 5 Albania Europa 1957 59.3 1476505 1942. 6 Albania Europa 1962 64.8 1728137 2313. 7 Argelia África 1952 43.1 9279525 2449. 8 Argelia África 1957 45.7 10270856 3014. 9 Argelia África 1962 48.3 11000948 2551.10 Angola África 1952 30.0 4232095 3521.# … with 416 more rowsResumen
# todas las columnas menos "pib_per_capita"paises %>% select (-pib_per_capita)# las columnas entre 'pais' y 'esperanza_de_vida'paises %>% select (pais:esperanza_de_vida)# usa "&" cuando hay mas que una condicionpaises %>% filter (anio==1982 & pais=="Ecuador")# usa "!" cuando no quieres specificas lineaspaises %>% filter (!pais=="Francia")# usa "%in%" cuando una variable pertenece a un vector paises %>% filter (pais %in% c("China", "Japan", "Vietnam")RENAME
La funcion RENAME permite de cambiar el nombre de una variable
paises %>% rename(esperanza = esperanza_de_vida, pib= pib_per_capita)# A tibble: 1,704 × 6 pais continente anio esperanza poblacion pib <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Afganistán Asia 1972 36.1 13079460 740. 6 Afganistán Asia 1977 38.4 14880372 786. 7 Afganistán Asia 1982 39.9 12881816 978. 8 Afganistán Asia 1987 40.8 13867957 852. 9 Afganistán Asia 1992 41.7 16317921 649.10 Afganistán Asia 1997 41.8 22227415 635.# … with 1,694 more rowsConsejo: rename(nuevo_nombre = viejo_nombre)
ARRANGE
La funcion ARRANGE permite de ordernar filas
paises %>% arrange (esperanza_de_vida)# A tibble: 1,704 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Ruanda África 1992 23.6 7290203 737. 2 Afganistán Asia 1952 28.8 8425333 779. 3 Gambia África 1952 30 284320 485. 4 Angola África 1952 30.0 4232095 3521. 5 Sierra Leona África 1952 30.3 2143249 880. 6 Afganistán Asia 1957 30.3 9240934 821. 7 Camboya Asia 1977 31.2 6978607 525. 8 Mozambique África 1952 31.3 6446316 469. 9 Sierra Leona África 1957 31.6 2295678 1004.10 Burkina Faso África 1952 32.0 4469979 543.# … with 1,694 more rowspaises %>% arrange (desc(esperanza_de_vida))# A tibble: 1,704 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Japón Asia 2007 82.6 127467972 31656. 2 Hong Kong, China Asia 2007 82.2 6980412 39725. 3 Japón Asia 2002 82 127065841 28605. 4 Islandia Europa 2007 81.8 301931 36181. 5 Suiza Europa 2007 81.7 7554661 37506. 6 Hong Kong, China Asia 2002 81.5 6762476 30209. 7 Australia Oceanía 2007 81.2 20434176 34435. 8 España Europa 2007 80.9 40448191 28821. 9 Suecia Europa 2007 80.9 9031088 33860.10 Israel Asia 2007 80.7 6426679 25523.# … with 1,694 more rowspaises %>% arrange (continente,esperanza_de_vida)# A tibble: 1,704 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Ruanda África 1992 23.6 7290203 737. 2 Gambia África 1952 30 284320 485. 3 Angola África 1952 30.0 4232095 3521. 4 Sierra Leona África 1952 30.3 2143249 880. 5 Mozambique África 1952 31.3 6446316 469. 6 Sierra Leona África 1957 31.6 2295678 1004. 7 Burkina Faso África 1952 32.0 4469979 543. 8 Angola África 1957 32.0 4561361 3828. 9 Gambia África 1957 32.1 323150 521.10 Guinea Bissau África 1952 32.5 580653 300.# … with 1,694 more rowsUsa desc() por tener un orden descendente
USAR MULTIPLES FUNCIONES
paises# A tibble: 1,704 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Afganistán Asia 1972 36.1 13079460 740. 6 Afganistán Asia 1977 38.4 14880372 786. 7 Afganistán Asia 1982 39.9 12881816 978. 8 Afganistán Asia 1987 40.8 13867957 852. 9 Afganistán Asia 1992 41.7 16317921 649.10 Afganistán Asia 1997 41.8 22227415 635.# … with 1,694 more rowspaises %>% select (continente, pais,anio, poblacion,esperanza_de_vida)# A tibble: 1,704 × 5 continente pais anio poblacion esperanza_de_vida <fct> <fct> <int> <int> <dbl> 1 Asia Afganistán 1952 8425333 28.8 2 Asia Afganistán 1957 9240934 30.3 3 Asia Afganistán 1962 10267083 32.0 4 Asia Afganistán 1967 11537966 34.0 5 Asia Afganistán 1972 13079460 36.1 6 Asia Afganistán 1977 14880372 38.4 7 Asia Afganistán 1982 12881816 39.9 8 Asia Afganistán 1987 13867957 40.8 9 Asia Afganistán 1992 16317921 41.710 Asia Afganistán 1997 22227415 41.8# … with 1,694 more rowspaises %>% select (continente, pais,anio, poblacion,esperanza_de_vida) %>% filter (continente == "Américas", anio >=1980, pais %in% c("Ecuador", "México", "Argentina"))# A tibble: 18 × 5 continente pais anio poblacion esperanza_de_vida <fct> <fct> <int> <int> <dbl> 1 Américas Argentina 1982 29341374 69.9 2 Américas Argentina 1987 31620918 70.8 3 Américas Argentina 1992 33958947 71.9 4 Américas Argentina 1997 36203463 73.3 5 Américas Argentina 2002 38331121 74.3 6 Américas Argentina 2007 40301927 75.3 7 Américas Ecuador 1982 8365850 64.3 8 Américas Ecuador 1987 9545158 67.2 9 Américas Ecuador 1992 10748394 69.610 Américas Ecuador 1997 11911819 72.311 Américas Ecuador 2002 12921234 74.212 Américas Ecuador 2007 13755680 75.013 Américas México 1982 71640904 67.414 Américas México 1987 80122492 69.515 Américas México 1992 88111030 71.516 Américas México 1997 95895146 73.717 Américas México 2002 102479927 74.918 Américas México 2007 108700891 76.2paises %>% select (continente, pais,anio, poblacion,esperanza_de_vida) %>% filter (continente == "Américas", anio >=1980, pais %in% c("Ecuador", "México", "Argentina")) %>% rename (esperanza = esperanza_de_vida)# A tibble: 18 × 5 continente pais anio poblacion esperanza <fct> <fct> <int> <int> <dbl> 1 Américas Argentina 1982 29341374 69.9 2 Américas Argentina 1987 31620918 70.8 3 Américas Argentina 1992 33958947 71.9 4 Américas Argentina 1997 36203463 73.3 5 Américas Argentina 2002 38331121 74.3 6 Américas Argentina 2007 40301927 75.3 7 Américas Ecuador 1982 8365850 64.3 8 Américas Ecuador 1987 9545158 67.2 9 Américas Ecuador 1992 10748394 69.610 Américas Ecuador 1997 11911819 72.311 Américas Ecuador 2002 12921234 74.212 Américas Ecuador 2007 13755680 75.013 Américas México 1982 71640904 67.414 Américas México 1987 80122492 69.515 Américas México 1992 88111030 71.516 Américas México 1997 95895146 73.717 Américas México 2002 102479927 74.918 Américas México 2007 108700891 76.2MUTATE
La funcion MUTATE permite de añadir nuevas columnas
paises# A tibble: 1,704 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Afganistán Asia 1972 36.1 13079460 740. 6 Afganistán Asia 1977 38.4 14880372 786. 7 Afganistán Asia 1982 39.9 12881816 978. 8 Afganistán Asia 1987 40.8 13867957 852. 9 Afganistán Asia 1992 41.7 16317921 649.10 Afganistán Asia 1997 41.8 22227415 635.# … with 1,694 more rowspaises %>% mutate (poblacion_k = poblacion/1000)# A tibble: 1,704 × 7 pais continente anio esperanza_de_vi… poblacion pib_per_capita poblacion_k <fct> <fct> <int> <dbl> <int> <dbl> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 8425. 2 Afganistán Asia 1957 30.3 9240934 821. 9241. 3 Afganistán Asia 1962 32.0 10267083 853. 10267. 4 Afganistán Asia 1967 34.0 11537966 836. 11538. 5 Afganistán Asia 1972 36.1 13079460 740. 13079. 6 Afganistán Asia 1977 38.4 14880372 786. 14880. 7 Afganistán Asia 1982 39.9 12881816 978. 12882. 8 Afganistán Asia 1987 40.8 13867957 852. 13868. 9 Afganistán Asia 1992 41.7 16317921 649. 16318.10 Afganistán Asia 1997 41.8 22227415 635. 22227.# … with 1,694 more rowspaises %>% mutate (poblacion_k = poblacion/1000)# A tibble: 1,704 × 7 pais continente anio esperanza_de_vi… poblacion pib_per_capita poblacion_k <fct> <fct> <int> <dbl> <int> <dbl> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 8425. 2 Afganistán Asia 1957 30.3 9240934 821. 9241. 3 Afganistán Asia 1962 32.0 10267083 853. 10267. 4 Afganistán Asia 1967 34.0 11537966 836. 11538. 5 Afganistán Asia 1972 36.1 13079460 740. 13079. 6 Afganistán Asia 1977 38.4 14880372 786. 14880. 7 Afganistán Asia 1982 39.9 12881816 978. 12882. 8 Afganistán Asia 1987 40.8 13867957 852. 13868. 9 Afganistán Asia 1992 41.7 16317921 649. 16318.10 Afganistán Asia 1997 41.8 22227415 635. 22227.# … with 1,694 more rowsTener la poblacion en miles (K)
SUMMARIZE Y GROUP_BY
Permiten dividir y resumir los datos en grupos
Ejemplo 1: ¿ Cual es la esperanza de vida media POR continente ?
paises# A tibble: 1,704 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Afganistán Asia 1972 36.1 13079460 740. 6 Afganistán Asia 1977 38.4 14880372 786. 7 Afganistán Asia 1982 39.9 12881816 978. 8 Afganistán Asia 1987 40.8 13867957 852. 9 Afganistán Asia 1992 41.7 16317921 649.10 Afganistán Asia 1997 41.8 22227415 635.# … with 1,694 more rowspaises %>% group_by(continente)# A tibble: 1,704 × 6# Groups: continente [5] pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Afganistán Asia 1972 36.1 13079460 740. 6 Afganistán Asia 1977 38.4 14880372 786. 7 Afganistán Asia 1982 39.9 12881816 978. 8 Afganistán Asia 1987 40.8 13867957 852. 9 Afganistán Asia 1992 41.7 16317921 649.10 Afganistán Asia 1997 41.8 22227415 635.# … with 1,694 more rowspaises %>% group_by(continente) %>% summarize(var=mean(esperanza_de_vida))# A tibble: 5 × 2 continente var <fct> <dbl>1 África 48.92 Américas 64.73 Asia 60.14 Europa 71.95 Oceanía 74.3Ejemplo 2: ¿ Cual es la esperanza de vida media POR continente y POR anio antes de los 70s ?
paises# A tibble: 1,704 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Afganistán Asia 1972 36.1 13079460 740. 6 Afganistán Asia 1977 38.4 14880372 786. 7 Afganistán Asia 1982 39.9 12881816 978. 8 Afganistán Asia 1987 40.8 13867957 852. 9 Afganistán Asia 1992 41.7 16317921 649.10 Afganistán Asia 1997 41.8 22227415 635.# … with 1,694 more rowspaises %>% filter(anio <1970)# A tibble: 568 × 6 pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Albania Europa 1952 55.2 1282697 1601. 6 Albania Europa 1957 59.3 1476505 1942. 7 Albania Europa 1962 64.8 1728137 2313. 8 Albania Europa 1967 66.2 1984060 2760. 9 Argelia África 1952 43.1 9279525 2449.10 Argelia África 1957 45.7 10270856 3014.# … with 558 more rowspaises %>% filter(anio <1970) %>% group_by(continente,anio)# A tibble: 568 × 6# Groups: continente, anio [20] pais continente anio esperanza_de_vida poblacion pib_per_capita <fct> <fct> <int> <dbl> <int> <dbl> 1 Afganistán Asia 1952 28.8 8425333 779. 2 Afganistán Asia 1957 30.3 9240934 821. 3 Afganistán Asia 1962 32.0 10267083 853. 4 Afganistán Asia 1967 34.0 11537966 836. 5 Albania Europa 1952 55.2 1282697 1601. 6 Albania Europa 1957 59.3 1476505 1942. 7 Albania Europa 1962 64.8 1728137 2313. 8 Albania Europa 1967 66.2 1984060 2760. 9 Argelia África 1952 43.1 9279525 2449.10 Argelia África 1957 45.7 10270856 3014.# … with 558 more rowspaises %>% filter(anio <1970) %>% group_by(continente,anio) %>% summarize(var=mean(esperanza_de_vida))# A tibble: 20 × 3# Groups: continente [5] continente anio var <fct> <int> <dbl> 1 África 1952 39.1 2 África 1957 41.3 3 África 1962 43.3 4 África 1967 45.3 5 Américas 1952 53.3 6 Américas 1957 56.0 7 Américas 1962 58.4 8 Américas 1967 60.4 9 Asia 1952 46.310 Asia 1957 49.311 Asia 1962 51.612 Asia 1967 54.713 Europa 1952 64.414 Europa 1957 66.715 Europa 1962 68.516 Europa 1967 69.717 Oceanía 1952 69.318 Oceanía 1957 70.319 Oceanía 1962 71.120 Oceanía 1967 71.3EJEMPLO CON OTROS DATOS 🛩
#install.packages("datos")library(datos)vueloshead(vuelos,n =10)# A tibble: 10 × 19 anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 1 1 517 515 2 2 2013 1 1 533 529 4 3 2013 1 1 542 540 2 4 2013 1 1 544 545 -1 5 2013 1 1 554 600 -6 6 2013 1 1 554 558 -4 7 2013 1 1 555 600 -5 8 2013 1 1 557 600 -3 9 2013 1 1 557 600 -310 2013 1 1 558 600 -2# … with 13 more variables: horario_llegada <int>, llegada_programada <int>,# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,# hora <dbl>, minuto <dbl>, fecha_hora <dttm>¿Cual es el atraso medio a la llegada por aerolinea ? 🤔
vuelos# A tibble: 336,776 × 19 anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 1 1 517 515 2 2 2013 1 1 533 529 4 3 2013 1 1 542 540 2 4 2013 1 1 544 545 -1 5 2013 1 1 554 600 -6 6 2013 1 1 554 558 -4 7 2013 1 1 555 600 -5 8 2013 1 1 557 600 -3 9 2013 1 1 557 600 -310 2013 1 1 558 600 -2# … with 336,766 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% group_by(aerolinea)# A tibble: 336,776 × 19# Groups: aerolinea [16] anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 1 1 517 515 2 2 2013 1 1 533 529 4 3 2013 1 1 542 540 2 4 2013 1 1 544 545 -1 5 2013 1 1 554 600 -6 6 2013 1 1 554 558 -4 7 2013 1 1 555 600 -5 8 2013 1 1 557 600 -3 9 2013 1 1 557 600 -310 2013 1 1 558 600 -2# … with 336,766 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% group_by(aerolinea) %>% summarize( delay = mean(atraso_llegada,na.rm=TRUE) )# A tibble: 16 × 2 aerolinea delay <chr> <dbl> 1 9E 7.38 2 AA 0.364 3 AS -9.93 4 B6 9.46 5 DL 1.64 6 EV 15.8 7 F9 21.9 8 FL 20.1 9 HA -6.92 10 MQ 10.8 11 OO 11.9 12 UA 3.56 13 US 2.13 14 VX 1.76 15 WN 9.65 16 YV 15.6vuelos %>% group_by(aerolinea) %>% summarize( delay = mean(atraso_llegada,na.rm=TRUE) ) %>% arrange(desc(delay))# A tibble: 16 × 2 aerolinea delay <chr> <dbl> 1 F9 21.9 2 FL 20.1 3 EV 15.8 4 YV 15.6 5 OO 11.9 6 MQ 10.8 7 WN 9.65 8 B6 9.46 9 9E 7.38 10 UA 3.56 11 US 2.13 12 VX 1.76 13 DL 1.64 14 AA 0.36415 HA -6.92 16 AS -9.93¿Cual es el atraso medio a la llegada en San Francisco por aerolinea por cada mes del verano ☀️? 🤔
vuelos# A tibble: 336,776 × 19 anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 1 1 517 515 2 2 2013 1 1 533 529 4 3 2013 1 1 542 540 2 4 2013 1 1 544 545 -1 5 2013 1 1 554 600 -6 6 2013 1 1 554 558 -4 7 2013 1 1 555 600 -5 8 2013 1 1 557 600 -3 9 2013 1 1 557 600 -310 2013 1 1 558 600 -2# … with 336,766 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% filter(destino=="SFO")# A tibble: 13,331 × 19 anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 1 1 558 600 -2 2 2013 1 1 611 600 11 3 2013 1 1 655 700 -5 4 2013 1 1 729 730 -1 5 2013 1 1 734 737 -3 6 2013 1 1 745 745 0 7 2013 1 1 746 746 0 8 2013 1 1 803 800 3 9 2013 1 1 826 817 910 2013 1 1 1029 1030 -1# … with 13,321 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% filter(destino=="SFO") %>% filter(mes %in% c(6,7,8))# A tibble: 3,697 × 19 anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 6 1 559 600 -1 2 2013 6 1 622 628 -6 3 2013 6 1 653 700 -7 4 2013 6 1 729 730 -1 5 2013 6 1 741 740 1 6 2013 6 1 752 800 -8 7 2013 6 1 756 800 -4 8 2013 6 1 824 824 0 9 2013 6 1 924 915 910 2013 6 1 926 930 -4# … with 3,687 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% filter(destino=="SFO") %>% filter(mes %in% c(6,7,8)) %>% group_by(aerolinea, mes)# A tibble: 3,697 × 19# Groups: aerolinea, mes [15] anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 6 1 559 600 -1 2 2013 6 1 622 628 -6 3 2013 6 1 653 700 -7 4 2013 6 1 729 730 -1 5 2013 6 1 741 740 1 6 2013 6 1 752 800 -8 7 2013 6 1 756 800 -4 8 2013 6 1 824 824 0 9 2013 6 1 924 915 910 2013 6 1 926 930 -4# … with 3,687 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% filter(destino=="SFO") %>% filter(mes %in% c(6,7,8)) %>% group_by(aerolinea, mes) %>% summarize( delay = mean(atraso_llegada,na.rm=TRUE) )# A tibble: 15 × 3# Groups: aerolinea [5] aerolinea mes delay <chr> <int> <dbl> 1 AA 6 32.9 2 AA 7 21.7 3 AA 8 8.39 4 B6 6 24.1 5 B6 7 30.9 6 B6 8 2.58 7 DL 6 13.5 8 DL 7 24.8 9 DL 8 -5.3310 UA 6 17.2 11 UA 7 18.4 12 UA 8 6.2813 VX 6 35.1 14 VX 7 45.4 15 VX 8 -2.74vuelos %>% filter(destino=="SFO") %>% filter(mes %in% c(6,7,8)) %>% group_by(aerolinea, mes) %>% summarize( delay = mean(atraso_llegada,na.rm=TRUE) ) %>% arrange(desc(delay))# A tibble: 15 × 3# Groups: aerolinea [5] aerolinea mes delay <chr> <int> <dbl> 1 VX 7 45.4 2 VX 6 35.1 3 AA 6 32.9 4 B6 7 30.9 5 DL 7 24.8 6 B6 6 24.1 7 AA 7 21.7 8 UA 7 18.4 9 UA 6 17.2 10 DL 6 13.5 11 AA 8 8.3912 UA 8 6.2813 B6 8 2.5814 VX 8 -2.7415 DL 8 -5.33¿ Cuantos datos tenemos por destino ? 🤔
vuelos# A tibble: 336,776 × 19 anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 1 1 517 515 2 2 2013 1 1 533 529 4 3 2013 1 1 542 540 2 4 2013 1 1 544 545 -1 5 2013 1 1 554 600 -6 6 2013 1 1 554 558 -4 7 2013 1 1 555 600 -5 8 2013 1 1 557 600 -3 9 2013 1 1 557 600 -310 2013 1 1 558 600 -2# … with 336,766 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% group_by(destino)# A tibble: 336,776 × 19# Groups: destino [105] anio mes dia horario_salida salida_programada atraso_salida <int> <int> <int> <int> <int> <dbl> 1 2013 1 1 517 515 2 2 2013 1 1 533 529 4 3 2013 1 1 542 540 2 4 2013 1 1 544 545 -1 5 2013 1 1 554 600 -6 6 2013 1 1 554 558 -4 7 2013 1 1 555 600 -5 8 2013 1 1 557 600 -3 9 2013 1 1 557 600 -310 2013 1 1 558 600 -2# … with 336,766 more rows, and 13 more variables: horario_llegada <int>,# llegada_programada <int>, atraso_llegada <dbl>, aerolinea <chr>,# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,# fecha_hora <dttm>vuelos %>% group_by(destino) %>% summarize(datos_destino=n())# A tibble: 105 × 2 destino datos_destino <chr> <int> 1 ABQ 254 2 ACK 265 3 ALB 439 4 ANC 8 5 ATL 17215 6 AUS 2439 7 AVL 275 8 BDL 443 9 BGR 37510 BHM 297# … with 95 more rowsvuelos %>% group_by(destino) %>% summarize(datos_destino=n()) %>% arrange(desc(datos_destino))# A tibble: 105 × 2 destino datos_destino <chr> <int> 1 ORD 17283 2 ATL 17215 3 LAX 16174 4 BOS 15508 5 MCO 14082 6 CLT 14064 7 SFO 13331 8 FLL 12055 9 MIA 1172810 DCA 9705# … with 95 more rowsvuelos %>% group_by(destino) %>% summarize(datos_destino=n()) %>% arrange(desc(datos_destino))# A tibble: 105 × 2 destino datos_destino <chr> <int> 1 ORD 17283 2 ATL 17215 3 LAX 16174 4 BOS 15508 5 MCO 14082 6 CLT 14064 7 SFO 13331 8 FLL 12055 9 MIA 1172810 DCA 9705# … with 95 more rowsUsa n() por tener el tamaño actual del grupo.
PIVOT_LONGER
de un formato ancho a largo
relig_income# A tibble: 18 × 11 religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` `$75-100k` <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 Agnostic 27 34 60 81 76 137 122 2 Atheist 12 27 37 52 35 70 73 3 Buddhist 27 21 30 34 33 58 62 4 Catholic 418 617 732 670 638 1116 949 5 Don’t k… 15 14 15 11 10 35 21 6 Evangel… 575 869 1064 982 881 1486 949 7 Hindu 1 9 7 9 11 34 47 8 Histori… 228 244 236 238 197 223 131 9 Jehovah… 20 27 24 24 21 30 1510 Jewish 19 19 25 25 30 95 6911 Mainlin… 289 495 619 655 651 1107 93912 Mormon 29 40 48 51 56 112 8513 Muslim 6 7 9 10 9 23 1614 Orthodox 13 17 23 32 32 47 3815 Other C… 9 7 11 13 13 14 1816 Other F… 20 33 40 46 49 63 4617 Other W… 5 2 3 4 2 7 318 Unaffil… 217 299 374 365 341 528 407# … with 3 more variables: $100-150k <dbl>, >150k <dbl>,# Don't know/refused <dbl>relig_income %>% pivot_longer(!religion, names_to="income", values_to="count")# A tibble: 180 × 3 religion income count <chr> <chr> <dbl> 1 Agnostic <$10k 27 2 Agnostic $10-20k 34 3 Agnostic $20-30k 60 4 Agnostic $30-40k 81 5 Agnostic $40-50k 76 6 Agnostic $50-75k 137 7 Agnostic $75-100k 122 8 Agnostic $100-150k 109 9 Agnostic >150k 8410 Agnostic Don't know/refused 96# … with 170 more rowsPIVOT_WIDER
de un formato largo a ancho
fish_encounters# A tibble: 114 × 3 fish station seen <fct> <fct> <int> 1 4842 Release 1 2 4842 I80_1 1 3 4842 Lisbon 1 4 4842 Rstr 1 5 4842 Base_TD 1 6 4842 BCE 1 7 4842 BCW 1 8 4842 BCE2 1 9 4842 BCW2 110 4842 MAE 1# … with 104 more rowsfish_encounters %>% pivot_wider(names_from=station, values_from=seen)# A tibble: 19 × 12 fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE MAW <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> 1 4842 1 1 1 1 1 1 1 1 1 1 1 2 4843 1 1 1 1 1 1 1 1 1 1 1 3 4844 1 1 1 1 1 1 1 1 1 1 1 4 4845 1 1 1 1 1 NA NA NA NA NA NA 5 4847 1 1 1 NA NA NA NA NA NA NA NA 6 4848 1 1 1 1 NA NA NA NA NA NA NA 7 4849 1 1 NA NA NA NA NA NA NA NA NA 8 4850 1 1 NA 1 1 1 1 NA NA NA NA 9 4851 1 1 NA NA NA NA NA NA NA NA NA10 4854 1 1 NA NA NA NA NA NA NA NA NA11 4855 1 1 1 1 1 NA NA NA NA NA NA12 4857 1 1 1 1 1 1 1 1 1 NA NA13 4858 1 1 1 1 1 1 1 1 1 1 114 4859 1 1 1 1 1 NA NA NA NA NA NA15 4861 1 1 1 1 1 1 1 1 1 1 116 4862 1 1 1 1 1 1 1 1 1 NA NA17 4863 1 1 NA NA NA NA NA NA NA NA NA18 4864 1 1 NA NA NA NA NA NA NA NA NA19 4865 1 1 1 NA NA NA NA NA NA NA NASitios en español que tratan de dplyr 👩💻
https://es.r4ds.hadley.nz/transform.html#lo-b%C3%A1sico-de-dplyr
https://github.com/fdelaunay/tutorial-dplyr-es/blob/master/R/tutorial-dplyr.md